

Broadcom Breaking Down Big Data to Drive Data Flow Architecture
In 2014, IDC estimates that 1.7MB of data is being generated every minute for every person on the planet. Annual data generation is expected to increase by 40 percent year on year over the next decade, totaling 44 zettabytes (one zettabyte equals one trillion gigabytes) by 2020! Enterprises are accumulating and analyzing data for customer insights and decision-making, which in turn are resulting in more data and metadata, creating a cycle of exponential growth.
Innovative approaches to extract value from massive, almost unimaginable quantities of data requires a significant evolution and re-balancing of the datacenter, and is driving the transition from compute-centric architectures to data-flow architectures.
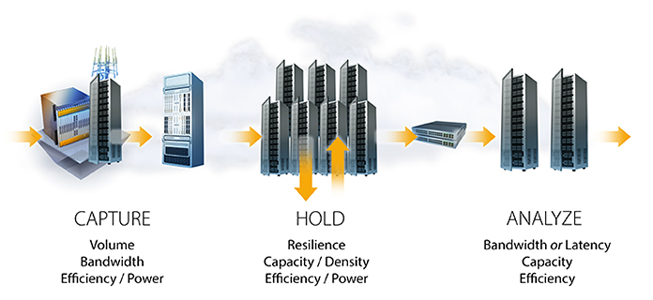
This shift requires a corresponding rethinking of storage architecture. To help understand where storage architecture is headed, breaking down analytics into three key phases illustrates the unique requirements of each phase and points out places where architectural similarities exist:
- In Capture multiple types, sizes and formats of raw data are acquired: data is pulled in, reformatted or transformed it as needed to prepare it for later use and analysis, and it is stored across multiple locations for reliability. The storage requirements at this phase usually demand high bandwidth in addition to low-cost and low-power consumption.
- In Hold, the data is stored it at the datacenter level, so it can be analyzed in aggregate to identify correlations. This demands a high-density, high-capacity but low-cost storage solution that uses very little power, and is very reliable at the aggregate or datacenter level.
- In the Analyze phase, value is extracted from data, typically using one of two general types of analytics. Bandwidth-based analytics includes massive amounts of data which are linearly traversed to identify patterns used to make business decisions (for example, Hadoop). Latency-based analytics involves traversing a huge number of individual, potentially small pieces of data, reading them and looking for correlations (for example, transactional workloads).
Today, server, storage and networking solutions for big data either leverage existing architectures or deploy a specific purpose-built platform based on the type of analytics being done. Providing a single solution that can address all three stages, while meeting requirements around bandwidth, latency, resource pooling, and cost, is the goal of rack scale storage architectures.